
Ilya错了?Scaling另有他用,ViT大佬力挺谷歌1000亿数据新发现
Ilya错了?Scaling另有他用,ViT大佬力挺谷歌1000亿数据新发现谷歌发布了1000亿文本-图像对数据集,是此前类似数据集的10倍,创下新纪录!基于新数据集,发现预训练Scaling Law,虽然对模型性能提升不明显,但对于小语种等其他指标提升明显。让ViT大佬翟晓华直呼新发现让人兴奋!
来自主题: AI技术研报
8202 点击 2025-03-10 09:52
 搜索
搜索
谷歌发布了1000亿文本-图像对数据集,是此前类似数据集的10倍,创下新纪录!基于新数据集,发现预训练Scaling Law,虽然对模型性能提升不明显,但对于小语种等其他指标提升明显。让ViT大佬翟晓华直呼新发现让人兴奋!

DeepSeek和xAI相继用R1和Grok-3证明:预训练Scaling Law不是OpenAI的护城河。将来95%的算力将用在推理,而不是现在的训练和推理各50%。OpenAI前途不明,生死难料!
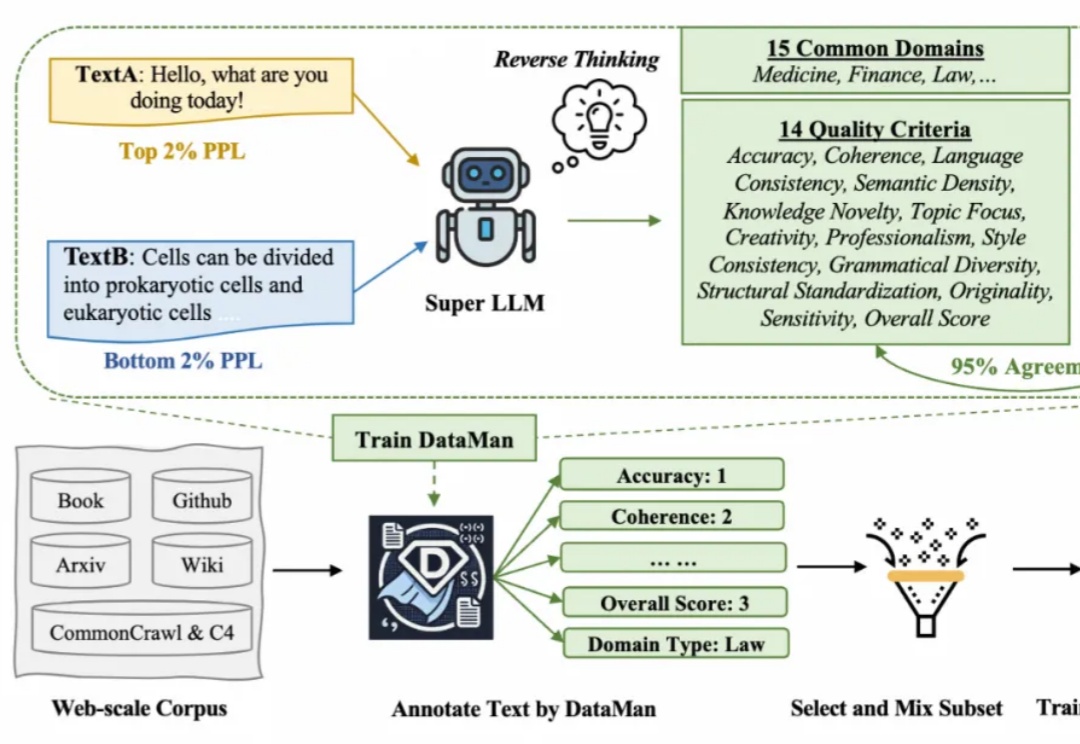
在 Scaling Law 背景下,预训练的数据选择变得越来越重要。然而现有的方法依赖于有限的启发式和人类的直觉,缺乏全面和明确的指导方针。在此背景下,该研究提出了一个数据管理器 DataMan,其可以从 14 个质量评估维度对 15 个常见应用领域的预训练数据进行全面质量评分和领域识别。

当 Scaling Law 在触顶边界徘徊之时,强化学习为构建更强大的大模型开辟出了一条新范式。
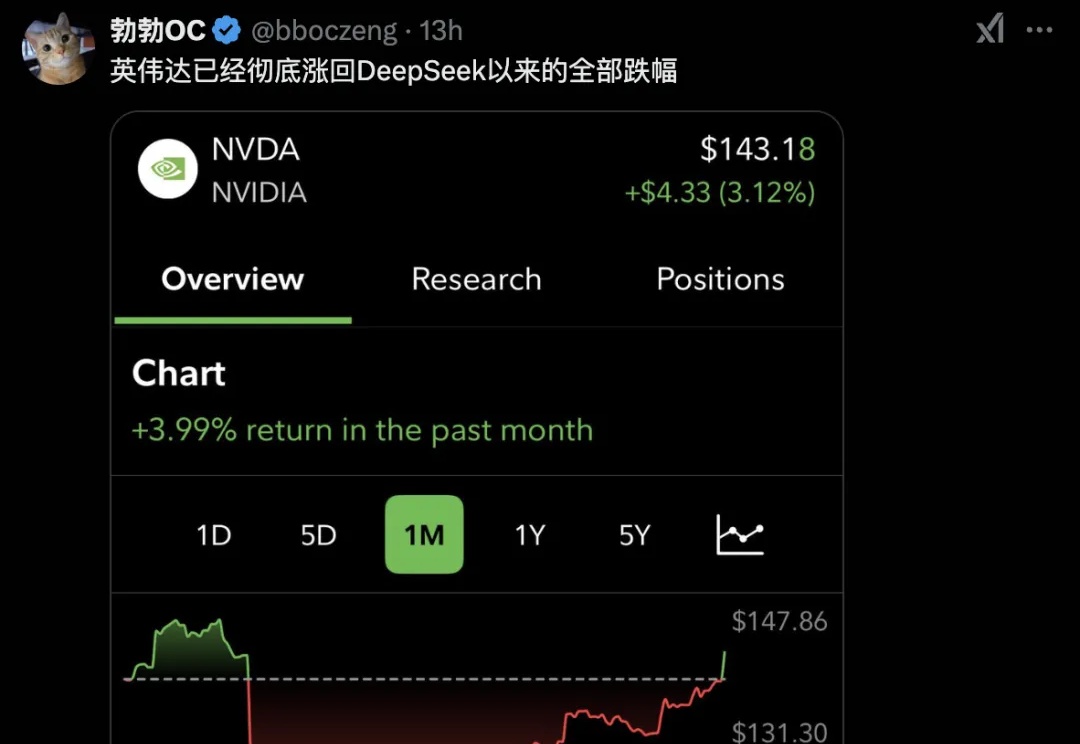
一度狂跌的英伟达股价,又被Grok-3盘活了?20万块GPU训出的模型超越DeepSeek和OpenAI,证明Scaling Law还在继续增长!Ai2研究者大佬直言:Grok-3,就是DeepSeek给美国AI企业压力的又一力证。

强化学习训练数据越多,模型推理能力就越强?新研究提出LIM方法,揭示提升推理能力的关键在于优化数据质量,而不是数据规模。该方法在小模型上优势尽显。从此,强化学习Scaling Law可能要被改写了!
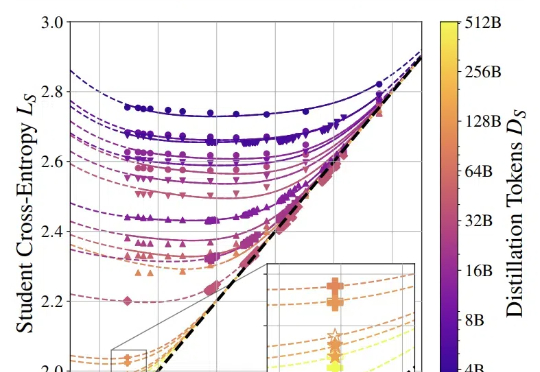
蒸馏模型的性能可以量化估算了。
刚刚,OpenAI奥特曼的最新AI观察出炉:Scaling Law将保持不变,短时间内没有理由停止对AI进行指数增长级的投资!1、AI能力与投入资源呈对数关系 2、AI使用成本每年降低约10倍 3、AI带来的社会经济价值呈超级指数增长
Ilya Sutskever 在 NeurIPS 会上直言:大模型预训练这条路可能已经走到头了。上周的 CES 2025,黄仁勋有提到,在英伟达看来,Scaling Laws 仍在继续,所有新 RTX 显卡都在遵循三个新的扩展维度:预训练、后训练和测试时间(推理),提供了更佳的实时视觉效果。

近日,资深机器学习研究科学家 Cameron R. Wolfe 更新了一篇超长的博客文章,详细介绍了 LLM scaling 的当前状况,并分享了他对 AI 研究未来的看法。